Understanding the Microsoft System Outage: Causes and Lessons Learned

Introduction
On July 19, 2024, a defective update to CrowdStrike's security software caused numerous Windows-based machines to crash and become unable to boot properly. The symptoms of the issue include the Blue Screen of Death (BSOD). As a result, numerous transportation, medical, finance and other tech services were disrupted and stuck due to this problem. This article will explain what happened and provide guidance on how to handle such issues in the future.Background
The defective update originated from CrowdStrike's Falcon sensor service, which offers real-time threat detection through endpoint protection. Unlike typical software running on Windows, Falcon sensor integrate deeply with the operating system using Kernel-Mode drivers. This low-level integration allows Falcon to operate in the background with full access to system operations. However, because Falcon integrates at the kernel level, critical issues can cause the entire operating system to crash. In this incident, the problem occurred at the kernel level, resulting in a Blue Screen of Death (BSOD) and causing the whole system to fail.Reversing the update
As of the time of writing this article, the faulty update has been removed by CrowdStrike. However, systems that were already affected are still experiencing the Blue Screen of Death (BSOD). Fixing these systems is challenging because they are stuck in a boot loop. The reason for this can be illustrated as follows: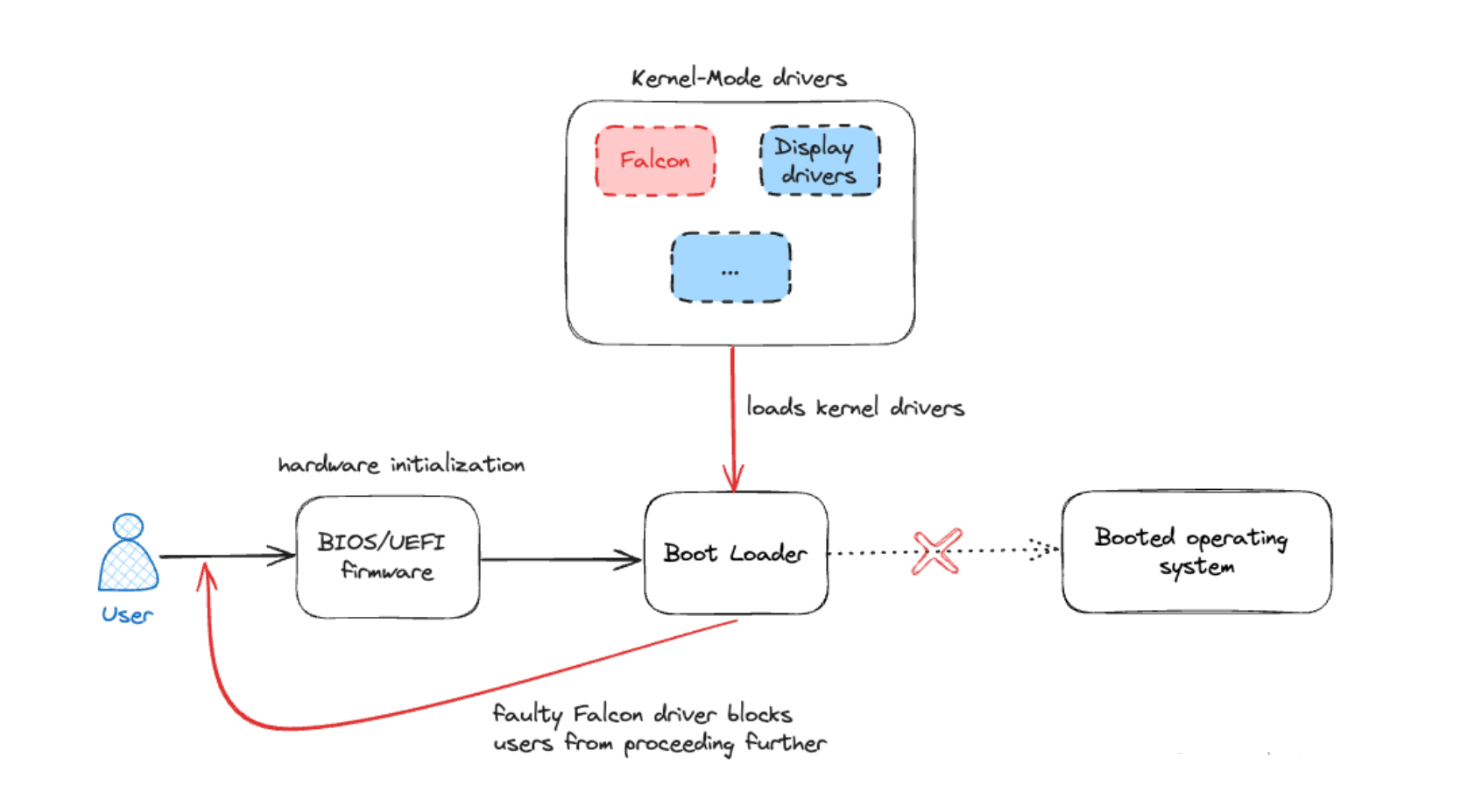
Lessons learned
This incident with the faulty update from CrowdStrike's Falcon service has highlighted several key lessons in software development, testing, and deployment, especially when dealing with critical system components such as kernel-mode drivers.Importance of Thorough Testing
One of the primary lessons learned is the necessity of thorough testing before deploying updates, particularly those that can cause panics in the system. Kernel-mode drivers have deep integration with the OS, meaning any malfunction can lead to severe system-wide issues. Therefore, it's crucial to conduct comprehensive testing in a controlled environment to identify potential faults. This includes stress testing, compatibility testing across different system configurations, and simulating real-world scenarios to ensure stability and reliability.Deployment Best Practices
Even with thorough pre-deployment testing, unforeseen issues can still arise. To mitigate the risk of widespread disruption, adopting best practices in deployment strategies is essential. One such strategy is canary deployment, where the update is initially rolled out to a small subset of users. This approach allows developers to monitor the update's performance in a live environment without impacting the entire user base. If issues are detected, the update can be rolled back quickly, minimizing the impact.Minimize Manual Intervention
The incident also underestimated the importance of having well-defined protocols for manual intervention. In cases where automated recovery is not possible, like the scenario where systems are stuck in a boot loop, having a clear, step-by-step manual recovery process is vital. This includes ensuring that support staff are trained and prepared to execute these manual interventions efficiently.Conclusion
Mistakes are an inevitable part of any complex system. It's important not to place blame on individuals or organizations but rather to focus on learning from these experiences. By analyzing what went wrong and understanding the underlying causes, we can implement better safeguards and improve our processes. This proactive approach ensures that our systems become more resilient and robust, minimizing the likelihood of similar incidents in the future. By embracing a culture of continuous improvement and vigilance, we can turn setbacks into valuable lessons and strengthen the reliability of our critical infrastructure.
S Weerasooriya
DevOps Engineer