Building a state-of-the-art ML inference API endpoint

TL;DR:
Machine Learning inferences take time, from a few seconds (X-to-text) to one minute (image-to-image). As a DevOps or MLOps engineer, you want to build a Model-as-a-Service (MaaS) that can scale up and down, be as cost effective as possible, and serve inference from API calls. If so, this article will describe the main components our engineers at Codimite deploy for such use-cases from our customers.Objectives:
- Containerized Software Development: Employing containerization for streamlined development, testing, and deployment of ML models.
- Integrate AI Models into business logic/product: Incorporating cutting-edge artificial intelligence models for advanced Computer Vision and Generative AI models to specific use cases, business use cases, with an easy to integrate and easy to sell "Model as a Service" solution.
- Kubernetes Engine Deployment: Leveraging Kubernetes for efficient container orchestration and management.
- Redundancy and Scalability: Implementing redundant systems to ensure high availability and scalability to handle varying workloads and different end-user traffic patterns.
Solution highlights
- Cloud Architecturing: cloud-based solution focused on optimizing response times for AI model inferences, aiming for peak performance, efficiency, and stability.
- Last-gen nVidia GPUs (L4s and A100s): Utilizing most recent nVidia GPUs for enhanced computational performance and accelerated AI processing.
- Redis-based Caching Engine: A custom-built caching engine leveraging Redis to enhance performance, particularly in the context of AI model inferences, contributing to reduced response times.
- Pub/Sub based queuing and messaging system: one FIFO queue per ML model, for inference requests to be picked up by the first available model container (each container acting as a "worker").
Challenges faced and solutions in details
Solution in detail
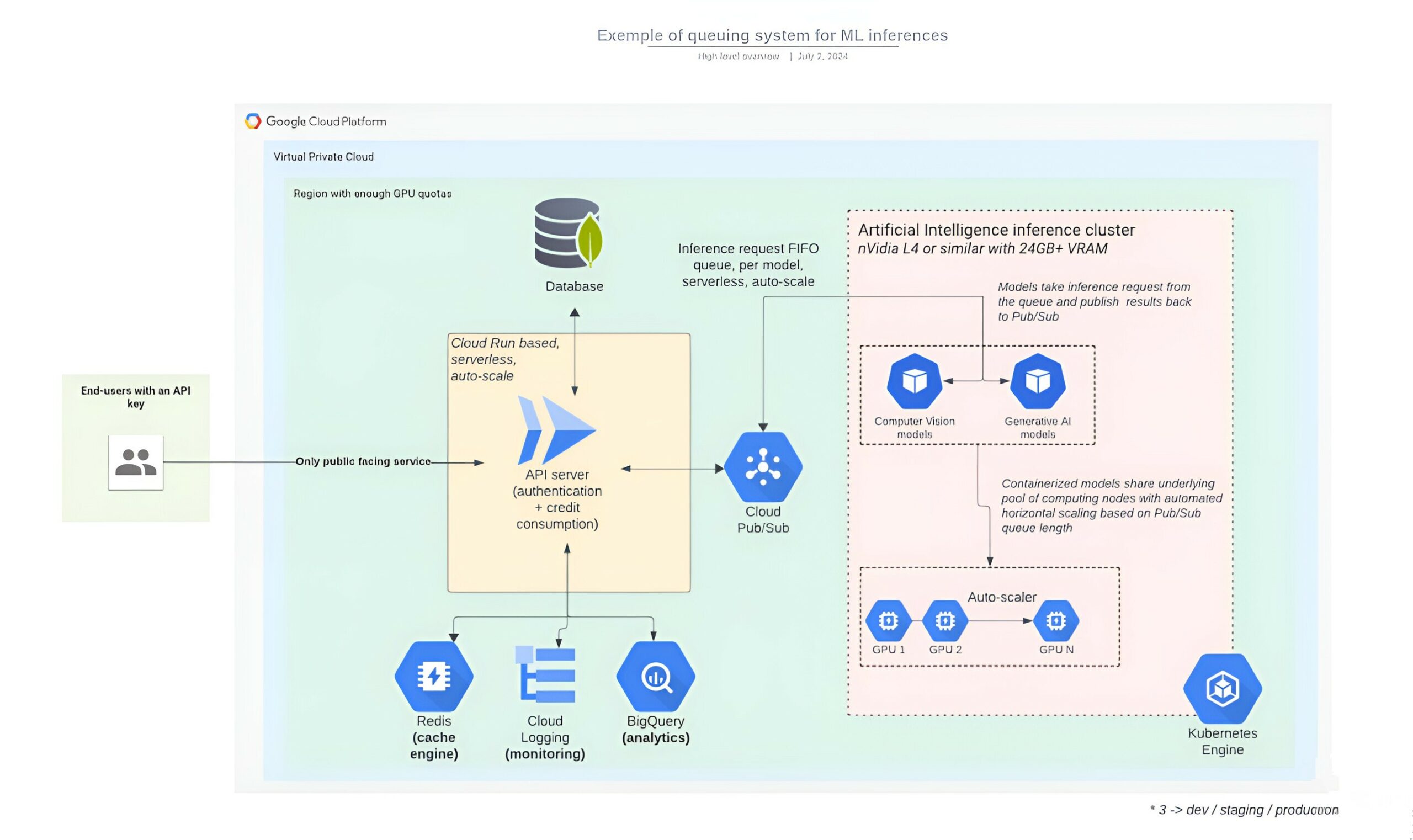
Speed-up containers scaling up
It is time consuming for a Kubernetes cluster to find spare capacity, provision a node in a cluster, and then load a model as a pod on the cluster. To speed this up, we'll be leveraging Kubernetes priority and preemption capabilities. That way, we will be able to provision buffer (GPU) capacity for Kubernetes (one with low priority) to evict as soon as one of the models (high-priority) will need to scale up. Here's a snippet of how priority classes would look like:apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: -10
preemptionPolicy: Never
globalDefault: false
description: "Low priority, used for extra capacity provisioning, will be evicted first"
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: default-priority
value: 0
preemptionPolicy: PreemptLowerPriority
globalDefault: true
description: "The global default priority."
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
preemptionPolicy: PreemptLowerPriority
globalDefault: false
description: "To be used by customer-facing pods only, e.g: CV and Generative AI models"
- An ML model deployment template will then be utilized to set any Deployment of an ML container with "high-priority".
- A capacity buffer will then be started with "low-priority", which will be evicted as soon as a model with "high-priority" needs to scale up; exemple below:
apiVersion: apps/v1
kind: Deployment
metadata:
name: capacity-reservation-deploy
spec:
replicas: 2
selector:
matchLabels:
app: capacity-reservation
template:
metadata:
labels:
app: capacity-reservation
spec:
priorityClassName: low-priority
terminationGracePeriodSeconds: 0
containers:
- name: ubuntu
image: ubuntu
command: <"sleep">
args: <"infinity">
resources:
requests:
nvidia.com/gpu: "1"
cpu: "3"
memory: "14G"
limits:
nvidia.com/gpu: "1"
Many-to-many relationship between Cloud Run instance (API server) and ML models instances
Pub/Sub leverages topics (what are we communicating about) as well as subscribers and publishers. The main challenge comes from the fact that, by default, every subscriber will receive every message published on the topic they are subscribed to, which can be inefficient and resource-consuming. Especially as the number of instances of a given API server scales up to meet user-facing demand.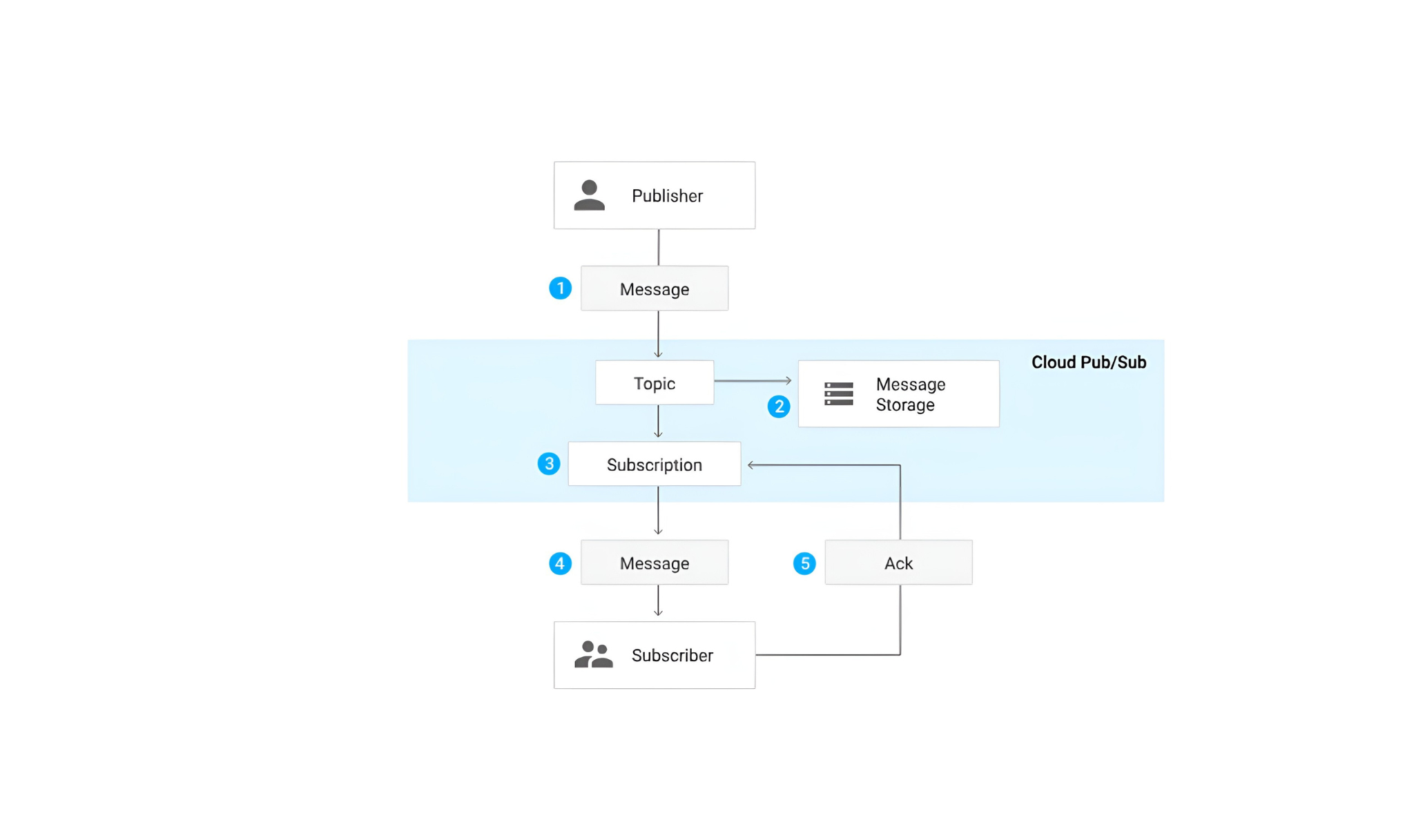
Multiple containers per GPU (nVidia time-share)
In scenarios where a typical inference flow involves calling different models sequentially, nVidia GPU time-share can be one of the levers to optimize the performance/cost ratio. Indeed, for flows involving calling different models one after another to serve a given API call, it doesn't make much sense for one model to be assigned a whole GPU, serve one inference, and then be idle while the rest of the sequential flow calls other models served by other GPUs. The whole flow could be served from a single GPU, being assigned to one model, and then assigned to the next model, and then the next one, etc.. always using just the same GPU. Here's an example of how we define a GKE cluster or a GKE node pool to make use of this feature:gcloud container clusters create gke-gpu-share-cluster --accelerator
"type=nvidia-l4,gpu-sharing-strategy=time-sharing,max-shared-clients-per-gpu=2,g
pu-driver-version=latest"
Benchmark and performance
The solution outlined above was able to achieve 1.4 millions inference a day in real-world, serving a real customer in Germany. This statistic was tracked using BigQuery, instrumented as part of the API server. To make this performance even better, most of the API calls involved Generative AI use cases with Stable Diffusion 1.5 models, image-to-image, one of the most computing-resource consuming generative AI use cases. At peak performance, 150+ L4 GPUs were provisioned and running in parallel from Google Cloud in order to meet end-user traffic.Ready to implement?
Schedule a call with our Codimite specialist, let's build your next state-of-the-art ML inference pipeline!
Data Science Team
Codimite